Learning To Speak: Key Components of a Neural TTS
Generally, a neural TTS has three key components: a text analysis module, an acoustic model, and a vocoder.
A previous post discussed the functions, importance, and subcomponents of a text analysis module. That post, however, looked at the TTS system from a traditional TTS perspective. In this post, I will try to explain, the best I can, how the entire neural TTS system works, from raw text to the final output: a waveform.
The neural TTS process is visualized in the illustration below. As can be seen here, the process is divided into 4 steps or subprocesses.
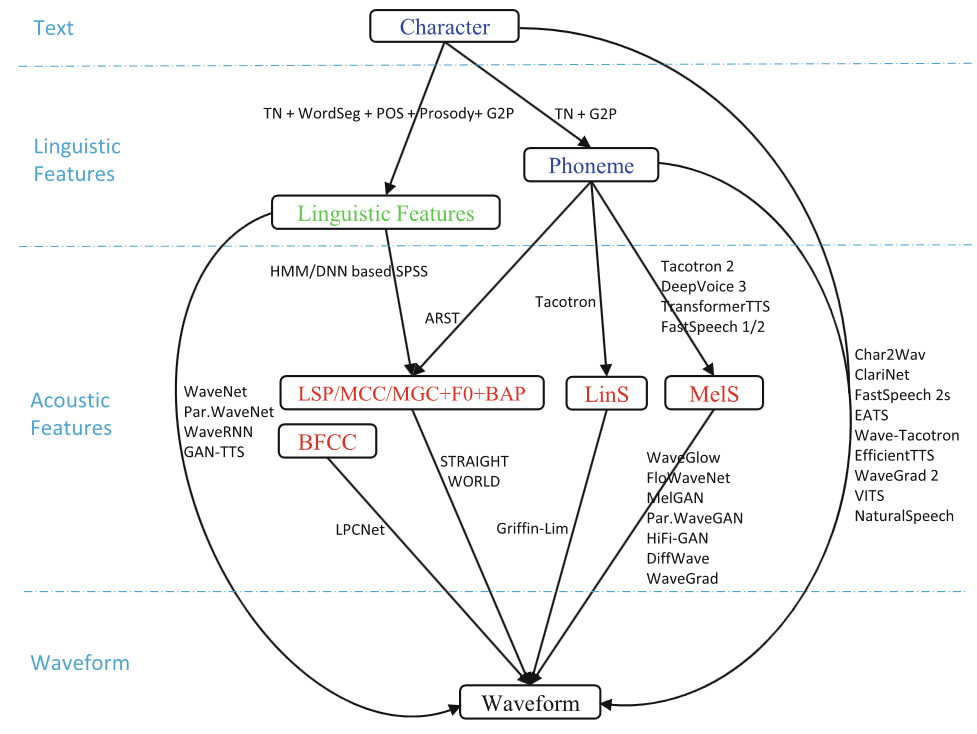
Figure 1: The data flows from text to waveform from [1]
To touch on the flow briefly before we going deep into it, this is basically how the process works from the first component to the last:
- The text analysis module processes, normalizes, and extracts information from the raw text,
- The acoustic models generate acoustic features from the output, which are ither phonemes or linguistic features, or both, of the previous module.
- The acoustic features generated by the acoustic models are then received by vocoders to generate speech or a waveform.
To have the full picture of the mechanism of a neural TTS, it is important to understand the data types received (as input) from other modules and each module’s output.
-
Characters - raw text received by the text analysis module. This is the input to the text analysis module and also the input to any TTS system.
The text analysis module will be explained in much greater depth in its own section. But for now, just to give an example of one of its functions (Part-of-Speech Tagging):
For example, the word produce could either be produce (verb) or produce (noun).
The difference in POS is important in determining how the word will be pronounced (whether PROduce or proDUCE).
-
Linguistic Features - information from the text during the processes in the text analysis module. When I say information, I mean elements such as the phonemes, the POS tags, etc.
So linguistic features are the output of the text analysis module and the input of the acoustic model(s).
-
Acoustic Features - In neural-based TTS models, mel-spectograms are usually used as acoustic features and are conversted to waveforms (speech) using neural-based vocoders.
-
Waveform - this is the main output of a TTS system. Also known as speech.

Figure 1: An illustration of a waveform from [2]
Even among neural-based TTS systems, there can be different data flows from text to waveform:
character->linguistic features->acoustic features->waveformcharacter->phoneme->avoustic features->waveformcharacter->linguistic features->waveformcharacter->phoneme->acoustic features->waveformcharacter->phoneme->waveformcharacter->waveform
Figure 1: Different neural TTS system architecture from [1]
In other posts, Text Analysis Modules, Acoustic Models, and Vocoders will be discussed in much greater depth.