Learning to Speak: How TTS Reads Texts
Text-to-Speech
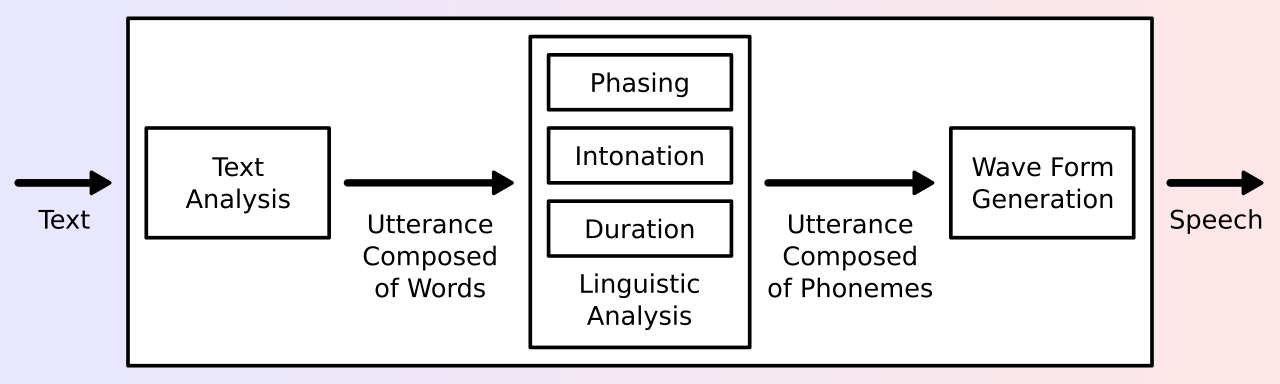
Figure 1: A typical TTS system architecture from [10]
While many of today’s TTS systems use neural models, the field started out with rules-based techniques. These technologies built the foundations for the Neural TTS systems used today. In this article, we explore the traditional TTS techniques architecture used in :
- Concatenative Synthesis,
- Formant Synthesis,
- Statistical Parametric Speech Synthesis (SPSS),
- etc.
Text-to-Speech synthesis or also known as Speech Synthesis is the process of generating human speech.
A text-to-speech (TTS) system converts normal normal language text into speech.
The reverse process is called speech recognition
What has been mostly used for TTS systems and what has been usually done before the advent of Neural TTS
A typical TTS system cosists of two basic processing modules [1]:
- text analysis module
- speech synthesis module
It is important to note that different sources divide the sections differently. For example, others separate Prosody prediction module and Acoustic model module [3].
In this post, we treat prosody prediction as a subcomponent of the text analysis module.
Text analysis Module
Text Analysis Module is a TTS System’s first module. This is where the raw text input goes for the speech (also called waveform) synthesis to process.
This module is responsible for converting the incoming text (raw text) into a linguistic representation. This stage is important for the standarization of linguistic features of a text.
In particular, this module has the following function:
-
Text Normalization and Preprocessing: For the speech/waveform synthesis module to be able to produce pronunciations and speech from the text input, the text analysis module should standardize the texts and any possible ambiguities of the inout text. For example, words of foreign origin or proper names with irregular pronunciations [1].
It handles numbers, dates, abbreviations, and other ambiguities. To give a real example, ‘1500 sq. ft.’, without this module, would be pronounced as ‘one five zero zero sq ft’, instead of the correct and understable version which would be ‘one-hundred-fifty square feet’.
With the example given above, I hope it is clear how important text normalization and preprocessing is. It basically creates a mapping for irregular or unpredictable pronunciations in the ‘vocabulary’.
-
Linguistic Analysis: The input of this module is the processed text from the text preprocessing and normalization.
This module, or should I say submodule, is responsible for extracting features relevant for pronunciation and prosody [5].
-
Grapheme-to-Phoneme (G2P) Conversion: This part of liguistic analysis is concerned with the correct pronunciation of words, hence the name. For clarity, graphemes are the smallest units of a writing system [6]. In English, and many other languages that uses the Latin alphabet, this could be as small as a letter or a group of letters that correspond to a sound, or more accurately, a phoneme [7]. For example, the word ‘should’ would have the graphemes: sh, oul, and d, since each of them corresponds to different sounds, or phonemes. G2P conversion can be achieved using the following [5]:
- Pronunciation Dictionaries (Lexicons)
- Rule-Based Systems
- Machine Learning Models
-
Part-of-Speech (POS) Tagging: While used for sentence or text understanding, POS is also helpful in determining the appropriate pronunciations of words spelled the same but are of different parts of speech.
For example, ‘content’ could mean either the adjective content (pronounced conTENT), meaning satisified, or the noun content (pronounced CONtent), meaning material within or part of something.
We, humans, could easily see the difference between these two words given the surrounding texts and the general context. TTS systems would need to be able to distinguish between the two using tagging to use the right pronunciation.
-
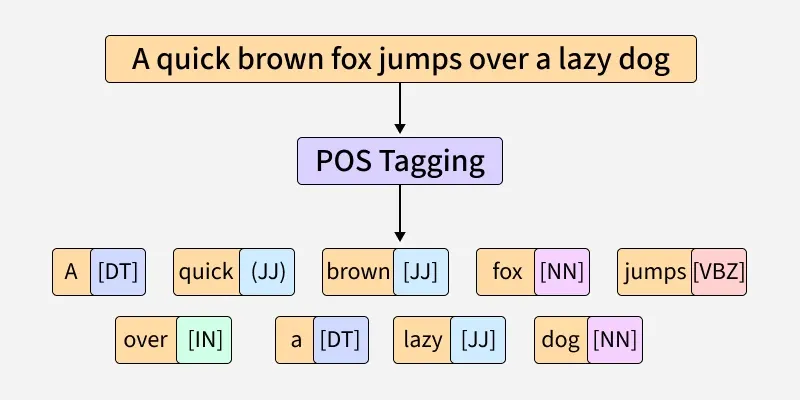
Figure 1: A visualization of Part-of-Speech Tagging from [11]
- Prosody Prediction: Prosody encompasses all the elements of language that has to do with its rhythm, and stress, which would not be inferred from the text/words alone [8].
The components of prosody are: intonation, stress, rhythm, and, tempo or pace.
The prosody prediction module receives the text from the two previous modules and predicts the appropriate pauses, breaks, and emphasis for a more natural-sounding speech.
The output is a sequence of phonemes with all the linguistic and prosodic information gathered from all the previous submodules. This includes the POS tags, prosody predictions, and phonemes of standardized words.
Waveform / Speech Synthesis Module
After the text has beeen processed and normalized, the Waveform Module then produces speech based on the information from the previous module and its submodules.
The aim of this module is to generate speech that resembles natural speech, free of noise and is highly intelligible.
The popular speech synthesis techniques are:
- Concatenative Synthesis
- Formant Synthesis
- Statistical Parametric Speech Synthesis
- Neural Speech Synthesis
Each of these techniques have different components and architecture that would be too long for a single article to cover.

Figure 1: A typical TTS system architecture from [1]
References
- https://speechprocessingbook.aalto.fi/Speech_Synthesis.html
- https://zilliz.com/ai-faq/how-does-a-text-analysis-module-work-in-tts
- https://www.sciencedirect.com/topics/computer-science/speech-synthesis-system
- http://research.spa.aalto.fi/publications/theses/lemmetty_mst/chap5.html
- https://apxml.com/courses/speech-recognition-synthesis-asr-tts/chapter-1-modern-speech-processing-foundations/tts-system-components
- https://en.wikipedia.org/wiki/Grapheme
- https://en.wikipedia.org/wiki/Phoneme
- https://en.wikipedia.org/wiki/Prosody_(linguistics)
- https://www.politesi.polimi.it/retrieve/a0ad5454-4e82-4041-a757-5660d683016e/Executive_Summary_Duration_Modelling_for_Expressive_TTS.pdf
- https://en.wikipedia.org/wiki/Speech_synthesis
- https://www.geeksforgeeks.org/nlp/nlp-part-of-speech-default-tagging/